Published in Syntaxus baccata
Author Lars Willighagen

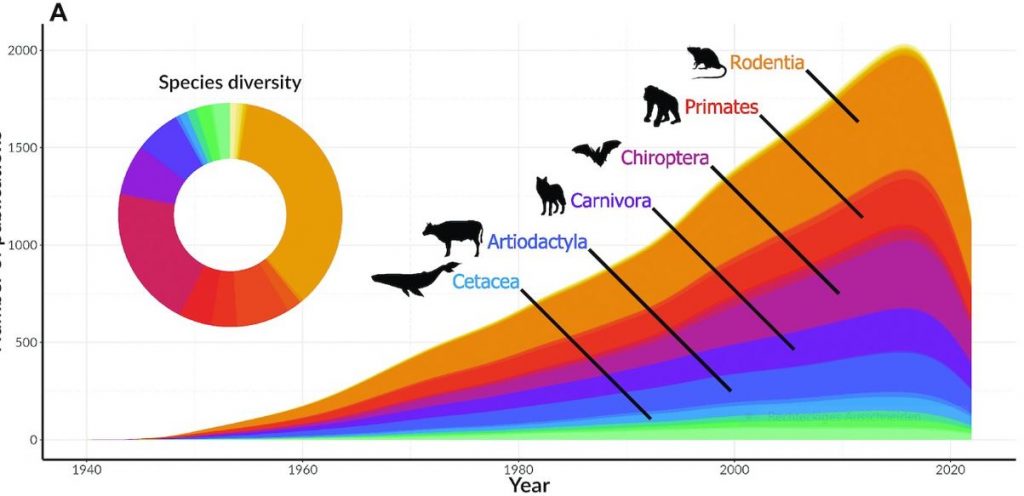
Working on translating a key to the European shield bug nymphs (Puchkov, 1961) I thought I would look for pictures of the earlier life stages (nymphs, Fig. 1) of shield bugs (Pentatomoidea) on iNaturalist and found few observations actually had the life stage annotation.